@byxiaoxie8 年前
07/22
16:01
HTML源代码:
<html xmlns=http://www.w3.org/1999/xhtml>
<meta http-equiv=Content-Type content="text/html;charset=utf-8">
<title>爬虫测试</title>
<head>
<body>
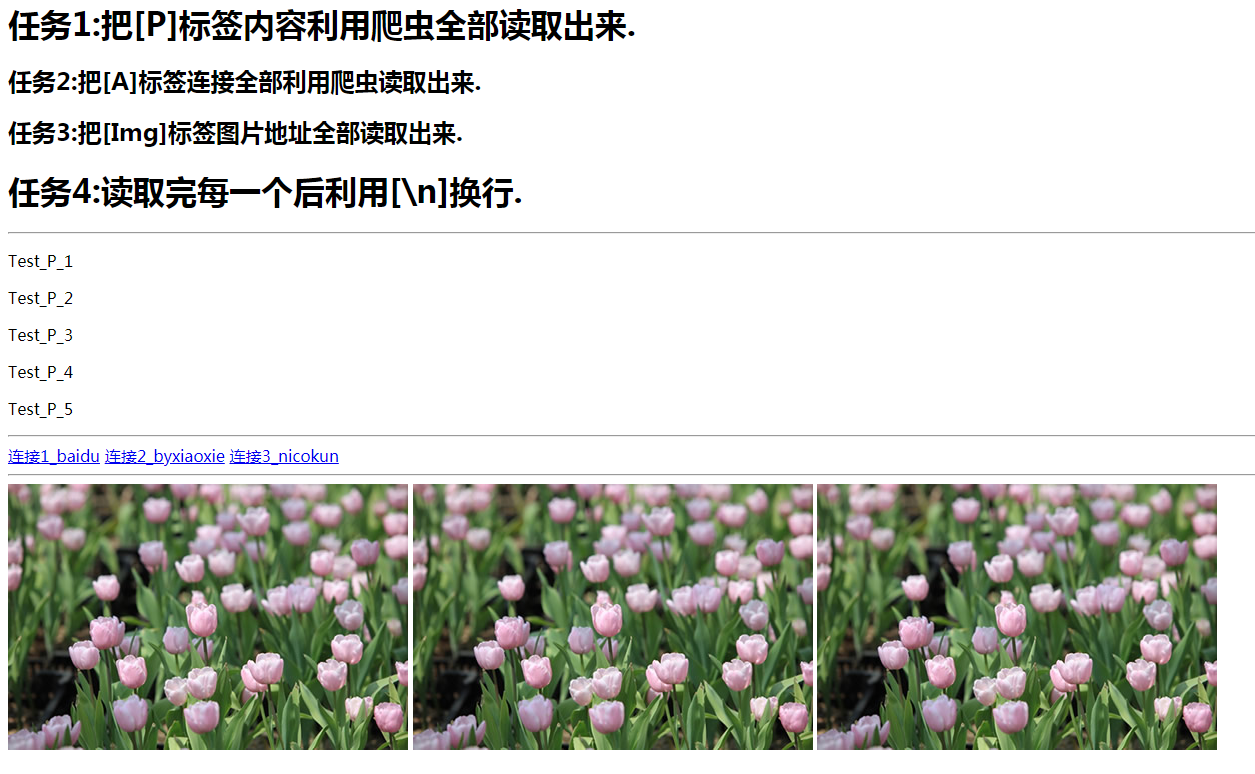
<h1>任务1:把[P]标签内容利用爬虫全部读取出来.</h1>
<h2>任务2:把[A]标签连接全部利用爬虫读取出来.</h2>
<h2>任务3:把[Img]标签图片地址全部读取出来.</h2>
<h1>任务4:读取完每一个后利用[\n]换行.</h1>
<hr>
<p>Test_P_1</p>
<p>Test_P_2</p>
<p>Test_P_3</p>
<p>Test_P_4</p>
<p>Test_P_5</p>
<hr>
<a href="https://baidu.com">连接1_baidu</a>
<a href="https://byxiaoxie.com">连接2_byxiaoxie</a>
<a href="http://xz.nicokun.com">连接3_nicokun</a>
<hr>
<img src="img_1.jpg" alt="图片1">
<img src="img_2.jpg" alt="图片2">
<img src="img_3.jpg" alt="图片3">
</body>
</head>
</html>
Python3 爬虫代码:
#!/usr/bin/nev python3
# -*- coding:utf-8 -*-
from urllib import request
from bs4 import BeautifulSoup
url = "http://192.168.10.250:66/test/"
open_web = request.urlopen(url).read().decode('utf-8') # 访问 url 地址取得网站源代码
#print(open_web) # 输出网站HTML源代码
html = BeautifulSoup(open_web,'html.parser') # 处理网站源代码
p_web = html.find_all('p') # 取源代码上的指定标签,取出来后为 数组 所以采用 for 来进行输出
a_web = html.find_all('a')
img_web = html.find_all('img')
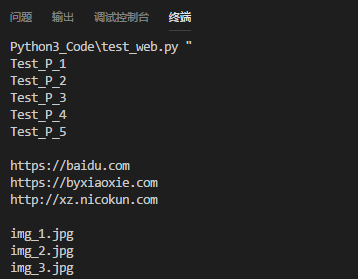
for p_ in p_web:
print(p_.string) # 输出所有 P 标签内容
print()
for a_ in a_web:
print(a_.get('href')) # 输出所有 a标签 href 属性的内容
print()
for img_ in img_web:
print(img_.get('src')) # 输出所有 src标签 src 属性的内容